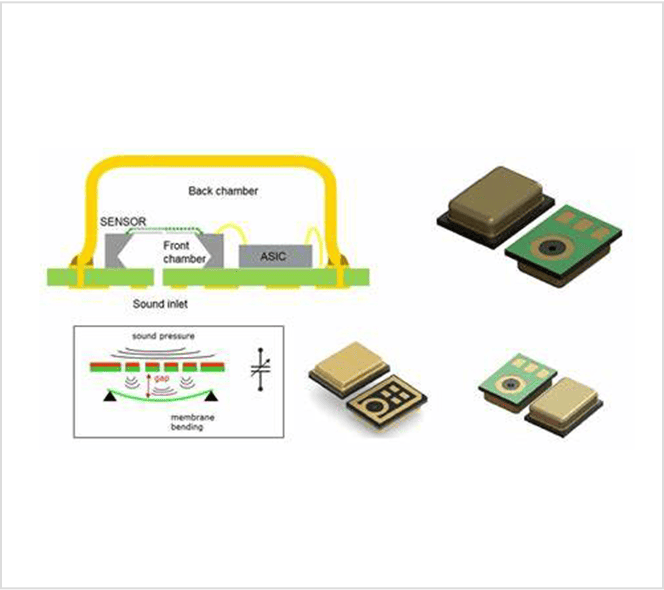
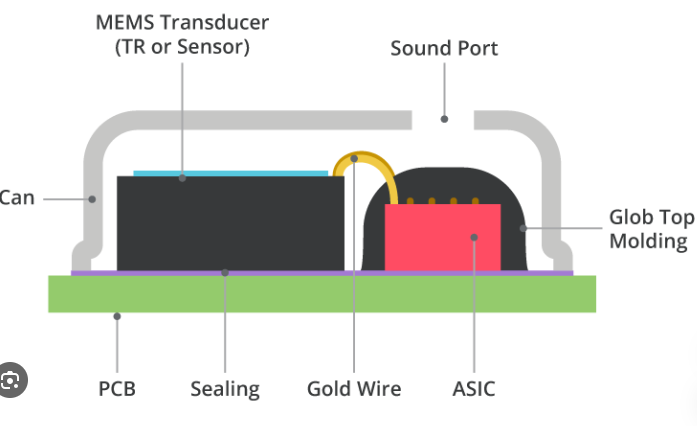
耳塞和助听器不再仅仅是音频配件,它们正在变成 微型计算机.从在嘈杂环境中清理通话、检测唤醒词、理解语音指令,到在拥挤的咖啡馆里跟随朋友的声音,现代听力设备要做的比以往任何时候都多。
挑战是什么?产品团队需要交付所有这些功能 不增加电池体积或硅片成本.解决方案在于 高效的人工智能计算与先进的智能 MEMS 麦克风 (MEMS MIC) 相结合 它能捕捉高保真音频,同时实现超低功耗的始终在线运行。
在 无锡硅源科技有限公司(SISTC)我们的 智能 MEMS 麦克风 旨在为这一听觉设备的多功能人工智能新时代提供支持。
框架盒:耳塞必须适合什么
现代耳塞和助听器正在融合,功能也在重叠:
- 实时语音增强 用于通话和面对面噪音抑制。
- 唤醒词检测 + SLU(口语理解) + 语音识别 实现免提控制。
- 自适应均衡、ANC 和反馈消除 实现卓越的音质。
- 健康和健身追踪 使用 IMU 和光学传感器。
但是,要在一个硬币大小的设备中实现所有这些功能,工程师们面临着严格的限制:
- 端到端音频延迟为 4-10 毫秒
- 始终监听的功能闲置在 微瓦级
- 有限的片上 SRAM 和闪存
这就是 智能 MEMS MIC + 压缩技术 进来
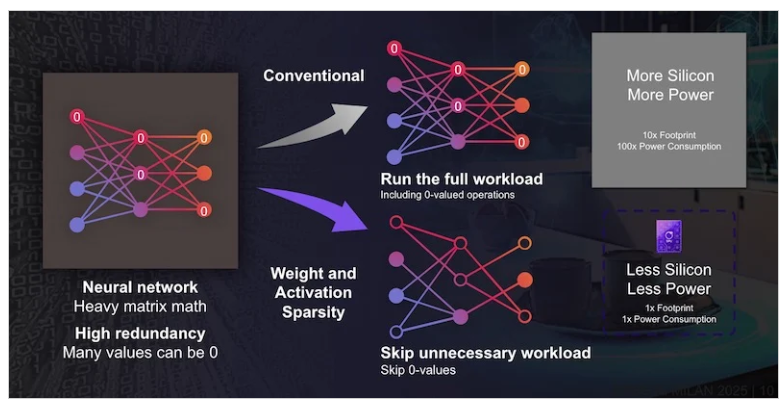
压缩是复数:适合的人工智能堆栈
要在微型硅片上运行多个人工智能模型,工程师们需要依靠 压缩技术堆栈:
- 量化 - 将模型大小最多缩小 4 倍(float32 → INT8),同时将质量损失降到最低。
- 权重稀疏性 - 削减参数多达 90%,减少内存和计算需求。
- 激活稀疏性 - 利用语音中的自然 "突发 "模式,跳过多余的操作。
- 建筑塑造 - 利用紧凑时序卷积(TCN)和递归神经网络(RNN)实现低延迟流式音频。
这些技术相结合,可以 有效运行次数减少 33 倍-使运行 语音增强、唤醒词检测、SLU 和 ANC 同时进行 低功耗耳塞。
一个具体实例:智能 MEMS MIC + 人工智能堆栈
典型的 语音增强模型 有 ~6M 个参数(浮点精度为 ~24 MB)。通过压缩
- 与 INT8 量化 → ~6 MB
- 与 90% 稀疏 → ~600 KB
- 激活重复使用 → ~700 KB 总占用空间
这种缩减可与其他模式(唤醒词、语音识别、ANC)共存。 1 MB SRAM 无外部 DRAM。
当与 智能 MEMS 麦克风因此,这个系统可以
- 运行 4-8 毫秒的低延迟去噪
- 仅消耗 1-2 毫瓦 用于始终保持运行状态
- 即使在多功能人工智能工作负载情况下也能延长电池寿命
👉 点击此处了解更多产品信息: 智能 MEMS 麦克风
智能 MEMS 麦克风为何重要
虽然压缩使人工智能变得可行、 音频质量从麦克风开始.MEMS MIC 技术可确保
- 高信噪比和低本底噪声这对准确识别语音至关重要。
- 宽动态范围 既适用于柔和的环境,也适用于嘈杂的环境。
- 低功耗运行 以达到压缩人工智能堆栈的效率。
智能微机电系统 MIC 不仅仅是传感器,它们还是 人工智能促进因素.通过捕捉更纯净的信号,它们可以降低下游模型的复杂性,并有助于在功耗和内存预算紧张的情况下实现可靠的性能。
展望未来
由于 可听设备汇聚人工智能功能在这一合作中 高效的人工智能模型 和 先进的智能 MEMS 麦克风 将定义下一代消费音频。
在 SISTC,我们致力于推动这一转变--帮助原始设备制造商在不增加电池预算的情况下,将更多的大脑装入新芽。
📖 相关阅读: