Introduction For decades, audio components in consumer electronics were relegated to “output modules”—the final link in a chain to play sound or deliver a notification. However, as we approach CES 2026, a fundamental shift is occurring. At Wuxi Silicon Source Technology (SISTC), our latest technical demonstrations signal a new era: Audio systems are evolving from passive executors into active, “perceiving” core computational units.
The catalyst? Edge AI.
1. The Paradigm Shift: Audio as the Entry Point for Edge AI
As Generative AI and edge computing mature, decision-making is moving from the cloud back to the device. The demands for low latency, privacy, and real-time response have made the “Edge” the new battleground.
Unlike visual data, audio signals are continuous, real-time, and high-frequency, making them ideal for persistent processing in low-power environments. This is why the first true “combat scenarios” for Edge AI are not in computer vision, but in voice, sound field, and environmental perception.
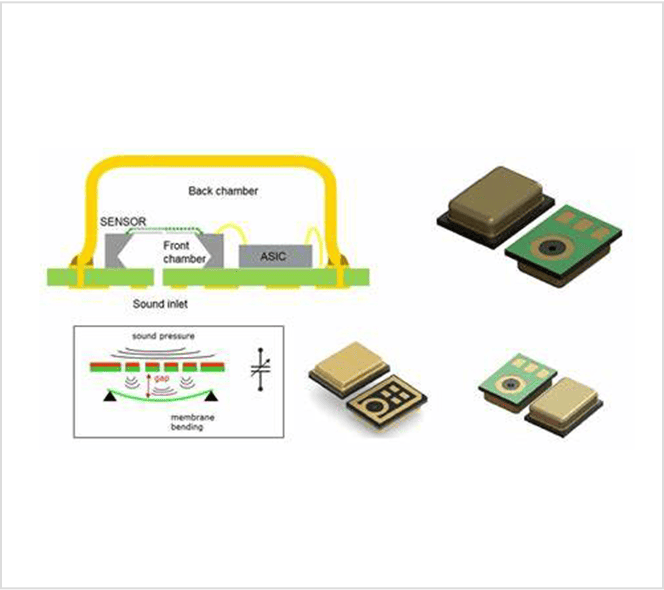
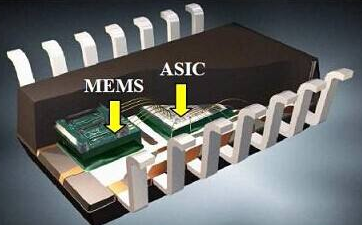
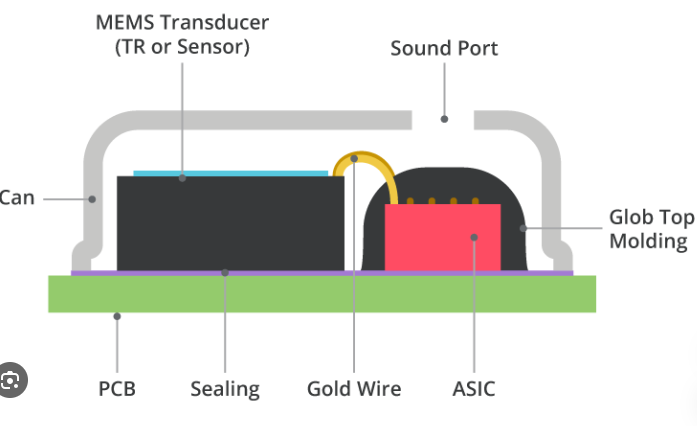
2. Hardware Redefined: The WBC-HRA381-M10 Smart Microphone

To meet this systemic shift, SISTC has developed the WBC-HRA381-M10. This is not just a microphone; it is a Smart Audio Sensing Node equipped with an integrated Neural Processing Unit (NPU).
Key Technical Specs for Edge AI Integration:
- Built-in NPU: Specialized for deep learning-based audio processing at the edge.
- Voice Activity Detection (VAD) & Keyword Spotting (KWS): Enables the system to “listen” with ultra-low power consumption (VAD+KWS Mode), waking up the host processor only when necessary.
- Integrated Analog Pre-processing (ASP): Ensures high-fidelity signal conditioning before AI inference.
- Versatile Interfaces: Supports I2C, SPI, and UART for seamless integration into distributed AI architectures.
Technical Insight: By moving VAD and KWS functions directly into the microphone hardware, the WBC-HRA381-M10 reduces system-wide latency and significantly extends battery life for wearables.
3. Software-Defined Audio & Spatial Intelligence
At CES 2026, SISTC is showcasing how Software-Defined Audio is rewriting hardware logic.
- Spatial Audio: Moving beyond simple 3D effects, our new solutions use synchronized high-precision timing to enable real-time sound source localization. Audio is no longer just an “atmosphere provider”; it is a “positional input” for XR and interactive entertainment.
- Digital-to-Analog Evolution: By leveraging edge computing and high-precision temporal control, we are demonstrating the possibility of high-quality conversion with reduced hardware complexity, shortening product iteration cycles for our partners.
4. Audio as System-Level Infrastructure
Our demonstrations of Audio over Ethernet (IP-based synchronization) prove that audio is now deeply bound with network and control systems. Whether in smart spaces or automotive cabins, audio has become a foundational infrastructure connecting “Device—Space—User.”
Conclusion: A New Sense for the AI Era The transformation we see at CES 2026 isn’t just about a single flashy feature. It is a strategic pivot: Audio is becoming the “First Sensory Organ” of intelligent systems. As a trusted partner with 15 years of innovation, SISTC is proud to lead this charge, delivering the MEMS and NPU-integrated solutions that allow machines to truly “understand” the world they hear.
Explore our full range of MEMS solutions at www.sistc.com.