With the rapid advancement of artificial intelligence, speech recognition has become one of the most important forms of human-computer interaction. The rise of embedded AI has brought speech recognition into a new era — enabling its integration into edge devices such as smart speakers, smartphones, wearables, and more.
Unlike traditional cloud-based systems, embedded AI allows for on-device processing and real-time inference, dramatically improving recognition speed and accuracy. It also enables reliable performance in offline or low-connectivity environments — a key requirement for many IoT and mobile scenarios.
The Role of MFCC in Speech Recognition
The Mel-Frequency Cepstral Coefficient (MFCC) is one of the most widely used algorithms for extracting audio features in speech recognition systems. By mimicking the human auditory system, MFCC transforms raw audio signals into a compact, frequency-based representation that captures key phonetic characteristics. This makes it robust to noise and distortion, particularly useful in embedded and mobile environments.
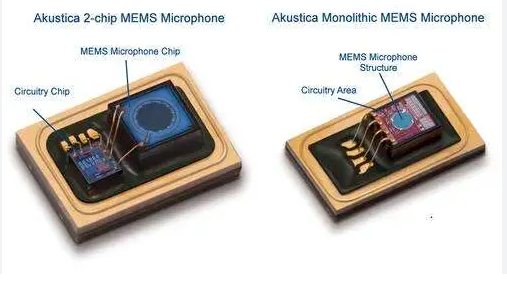
🔗 Learn more about our MEMS microphones optimized for speech and AI interfaces
Key Challenges in Embedded AI Speech Recognition
Despite the benefits, there are several design challenges that developers face when deploying AI-based speech systems on embedded devices:
- Limited Resources: Embedded devices often lack the memory or compute power required by complex AI models.
- Real-Time Processing: Fast response times demand low-latency algorithms and efficient audio pipelines.
- Environmental Robustness: Variability in ambient noise, echo, and distance can significantly affect accuracy.
- Multilingual Support: Global applications require flexible models capable of handling diverse accents and languages.
Technology Outlook and Future Directions
To overcome these limitations, ongoing research and commercial innovation are focusing on:
- Model Compression & Quantization: Techniques like pruning, weight sharing, and INT8 quantization reduce model size while preserving accuracy.
- Edge-Cloud Collaboration: Initial processing on-device with fallback to cloud-based inference for more complex tasks.
- Self-Adaptive Algorithms: AI that tunes itself based on environmental inputs (e.g., noise conditions).
- Multimodal Input Fusion: Combining speech with other sensory data (e.g., touch or vision) to improve contextual understanding.
Conclusion
Embedded AI speech recognition, especially using MFCC for feature extraction, is pushing the boundaries of what’s possible in portable and offline-capable smart devices. As hardware becomes more powerful and algorithms more efficient, we anticipate that embedded speech recognition will deliver faster, smarter, and more intuitive voice interaction.
Further Reading & External References:
- Voice Recognition Based on Adaptive MFCC and Deep Learning for Embedded Systems – ResearchGate
- Challenges and Limitations in Embedded Speech Recognition – ScienceDirect
- What is MFCC? – Wikipedia
💡 Looking for MEMS microphone solutions tailored for embedded AI and voice control?
Explore our full product range: https://sistc.com/product-category/mems-microphone/