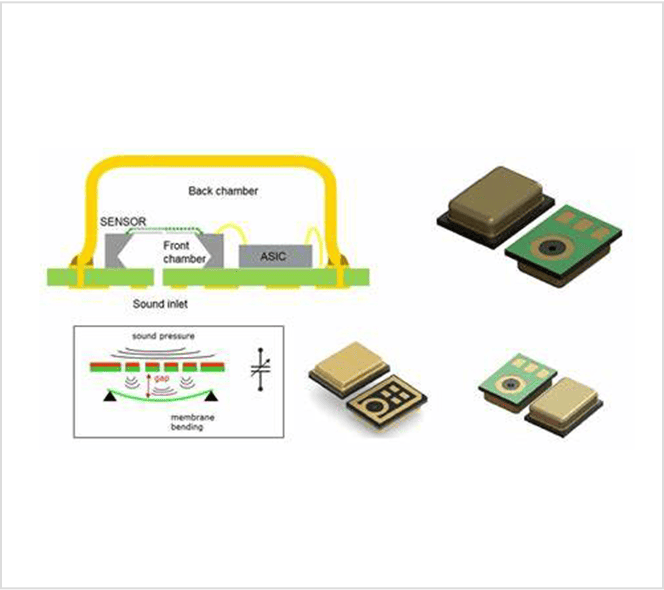
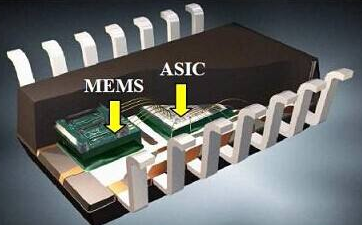
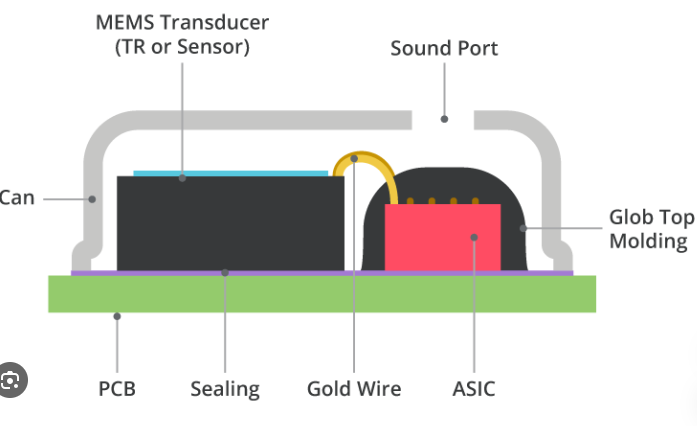
导言
随着人工智能深入日常生活,语音交互已成为智能设备的关键要素。传统的近场语音拾取(如 "靠近麦克风说话")已无法满足用户的期望。用户希望语音指令能 从几米远在 嘈杂环境和 有多个扬声器.
为了实现这一目标,数字 MEMS 麦克风阵列技术成为了该系统的核心。 远场语音交互.
人工智能语音系统中的麦克风阵列为何重要
与单个麦克风相比,麦克风阵列能够
- 空间选择性
通过估计到达方向 (DoA),该设备可以增强用户的声音并抑制不需要的方向。 - 扬声器跟踪
即使一个人在房间里走动,麦克风阵列也能检测到他说话的位置。 - 复杂环境下的卓越语音质量
阵列处理实现了三维时空过滤,从而提高了效率:- 噪音抑制
- 回声消除
- 混响抑制
- 语音分离
- 声源定位
如需了解 MEMS 麦克风产品,请访问:
https://www.sistc.com/product-category/mems-microphone/
探索麦克风阵列模块:
https://www.sistc.com/product-category/sensor-module/
麦克风阵列处理的技术挑战
尽管阵列信号处理已广泛应用于雷达和声纳领域,但麦克风阵列因声学信号的特性而有所不同。
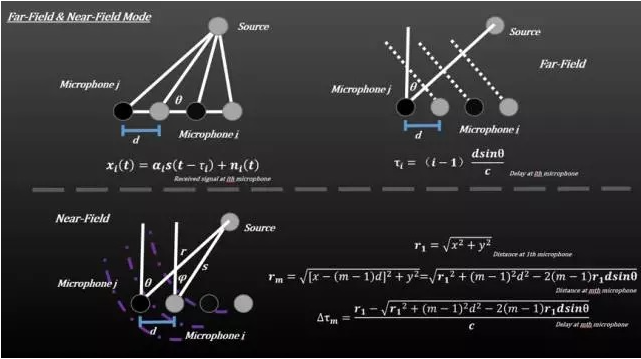
1.阵列建模(近场与远场)
- 语音拾取通常发生在 1-3 米即 近场.
- 与雷达/声纳远场平面波不同,音频信号是 球面波 振幅随距离衰减。
2.宽带信号处理
- 语音信号具有天然的宽带特性(丰富的低频和高频)。
- 延迟和相位差随频率变化,需要进行频域子波段处理。
3.非稳态信号处理
- 语音是随时间变化的。
- 阵列算法通过以下方式处理信号 短时傅立叶变换 (STFT) 并在每个频段运行。
4.混响
- 反射、衍射和多声道会降低语音清晰度。
- 需要波束成形和去混响算法。
声源定位
麦克风阵列通过将声音信号转换为空间坐标(二维或三维)来确定声音的来源。这样,设备就可以
- 将波束成形聚焦于扬声器
- 跟踪移动扬声器
- 将摄像机或机器人转向扬声器
有两种传播模式:
| 模型 | 距离 | 波浪型 |
|---|---|---|
| 近场 | 0-3 米(典型智能设备) | 球形 |
| 远场 | > 临界值:2L²/λ | 飞机 |
例如:
L = 阵列孔径
λ = 波长
声音定位算法
1.波束成形(空间滤波)
两种类型:
| 类型 | 说明 |
|---|---|
| CBF(传统波束成形) | 延迟求和法,简单,固定权重 |
| ABF(自适应波束成形) | 自动调节重量、抑制噪音、性能更高 |
自适应算法包括
- LMS(最小均方差)
- MVDR / LCMV(最小方差无失真响应)
主要优势
最大限度地提高扬声器方向的信噪比(SNR)。
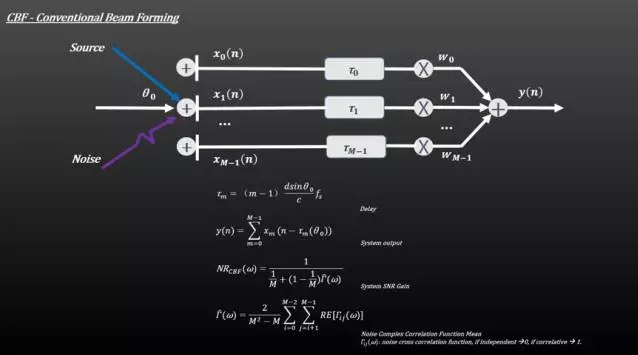
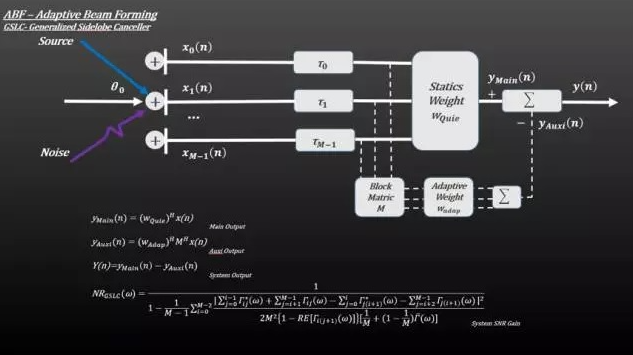
2.超分辨率频谱估计
这些算法包括
| 算法 | 优势 |
|---|---|
| 音乐 | 解决多声源问题 |
| ESPRIT | 无物理孔径限制的高分辨率 |
适用于多扬声器环境,但对模型误差敏感。
3.基于 TDOA(到达时间差)的定位
步骤:
- TDOA 估计
使用 GCC-PHAT(带相位变换的广义交叉相关技术)
参考文件(电气和电子工程师学会):
https://ieeexplore.ieee.org/document/506206 - 位置计算
利用距离差的几何交点
优势
- 只需 3 个麦克风
- 计算成本低
- 卓越的实时性能
广泛应用于远场语音产品(智能扬声器、会议设备)。
麦克风阵列技术的未来
麦克风阵列已成为智能音频和远场语音技术的基础。其应用包括
- 人工智能语音助手
- 智能家居设备
- 视频会议
- 服务机器人
- 汽车语音交互
- 可穿戴设备和助听器
未来的趋势是 跨模态融合结合:
- 语音识别
- 图像识别
- 面部和手势跟踪
- 波束成形和语音定位
当音频和视觉相互配合时,设备才能真正实现智能化。
进一步了解 MEMS 麦克风阵列
探索 SISTC MEMS 麦克风:
https://www.sistc.com/product-category/mems-microphone/
探索声学传声器阵列模块:
https://www.sistc.com/product-category/sensor-module/