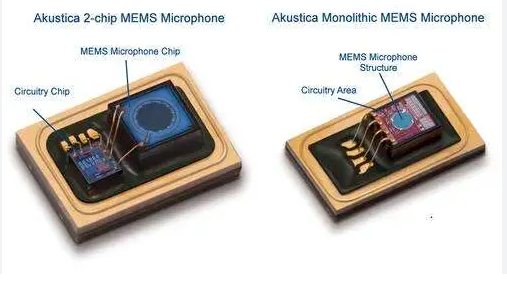
随着人工智能的飞速发展,语音识别已成为人机交互最重要的形式之一。嵌入式人工智能的兴起将语音识别带入了一个新时代,使其能够集成到智能扬声器、智能手机、可穿戴设备等边缘设备中。
与传统的云端系统不同,嵌入式人工智能可实现 设备上处理 与 实时推理这大大提高了识别速度和准确性。它还能在离线或低连接性环境中实现可靠的性能,这是许多物联网和移动应用场景的关键要求。
MFCC 在语音识别中的作用
SISTC的 梅尔频率倒频谱系数(MFCC) 是语音识别系统中提取音频特征最广泛使用的算法之一。通过模仿人类听觉系统,MFCC 将原始音频信号转换为一种紧凑的、基于频率的表示方法,从而捕捉到关键的语音特征。这使得它对噪音和失真具有很强的鲁棒性,在嵌入式和移动环境中尤其有用。
🔗 进一步了解我们的 针对语音和人工智能界面进行优化的 MEMS 麦克风
嵌入式人工智能语音识别的主要挑战
尽管好处多多,但在嵌入式设备上部署基于人工智能的语音系统时,开发人员仍面临一些设计挑战:
- 资源有限:嵌入式设备通常缺乏复杂人工智能模型所需的内存或计算能力。
- 实时处理:快速响应时间需要低延迟算法和高效音频流水线。
- 环境鲁棒性:环境噪声、回声和距离的变化会严重影响精确度。
- 多语言支持:全球应用需要能够处理不同口音和语言的灵活模型。
技术展望与未来方向
为了克服这些局限性,正在进行的研究和商业创新主要集中在以下几个方面:
- 模型压缩与量化:剪枝、权重共享和 INT8 量化等技术可在保持准确性的同时缩小模型尺寸。
- 边缘-云协作:在设备上进行初步处理,更复杂的任务可退回到云端推理。
- 自适应算法:根据环境输入(如噪音条件)进行自我调整的人工智能。
- 多模态输入融合:将语音与其他感官数据(如触觉或视觉)相结合,提高语境理解能力。
结论
嵌入式人工智能语音识别,特别是使用 MFCC 进行特征提取,正在推动便携式和离线智能设备的发展。随着硬件越来越强大,算法越来越高效,我们预计嵌入式语音识别将提供更快、更智能、更直观的语音交互。
更多阅读和外部参考资料:
💡 正在寻找专为嵌入式人工智能和语音控制定制的 MEMS 麦克风解决方案?
了解我们的全部产品系列: https://sistc.com/product-category/mems-microphone/