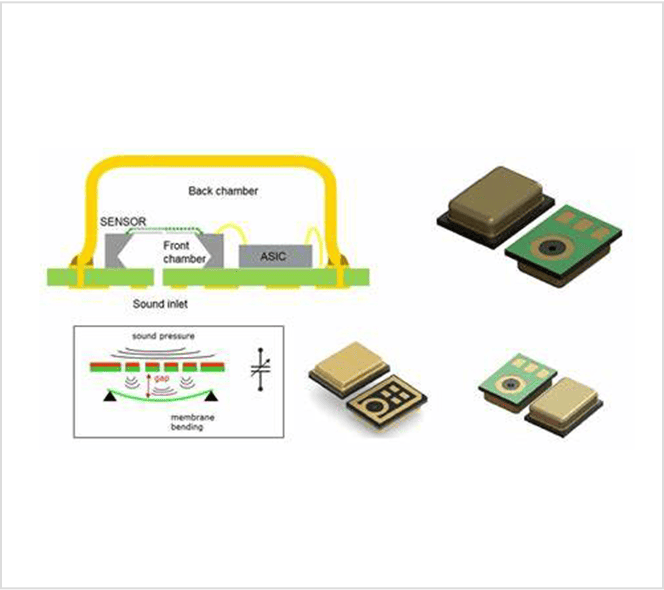
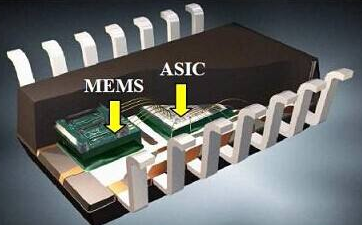
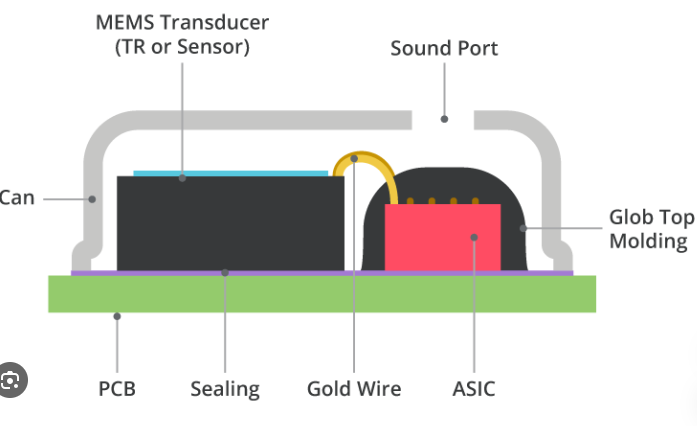
Earbuds and hearing aids are no longer just audio accessories—they’re turning into tiny computers. From cleaning up calls in noisy environments, detecting wake words, and understanding voice commands, to following a friend’s voice in a crowded café, modern hearables are expected to do more than ever.
The challenge? Product teams need to deliver all these features without increasing battery size or silicon cost. The solution lies in efficient AI computation combined with advanced Smart MEMS Microphones (MEMS MIC) that capture audio with high fidelity while enabling ultra-low-power always-on operation.
At Wuxi Silicon Source Technology (SISTC), our Smart MEMS Microphone is designed to support this new era of multi-feature AI in hearables.
The Constraint Box: What Has to Fit in Earbuds
Modern earbuds and hearing aids are converging, with overlapping feature sets:
- Real-time speech enhancement for calls and face-to-face noise suppression.
- Wake word detection + SLU (Spoken Language Understanding) + Voice ID for hands-free control.
- Adaptive EQ, ANC, and feedback cancellation for superior sound quality.
- Health and fitness tracking using IMU and optical sensors.
But to fit all of this in a device the size of a coin, engineers face tough constraints:
- End-to-end audio latencies of 4–10 ms
- Always-listening features idling at microwatt levels
- Limited on-chip SRAM and flash storage
That’s where Smart MEMS MIC + compression techniques come in.
Compression is Plural: The AI Stack That Fits
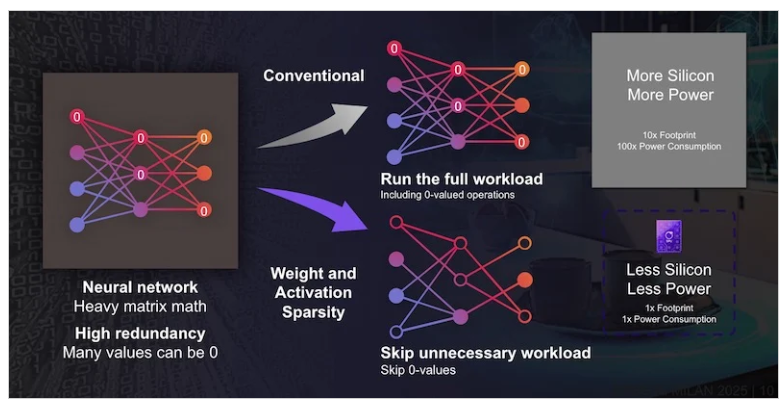
To make multiple AI models run on tiny silicon, engineers rely on a stack of compression techniques:
- Quantization – Reduces model size by up to 4× (float32 → INT8) with minimal quality loss.
- Weight sparsity – Cuts parameters up to 90%, reducing both memory and compute needs.
- Activation sparsity – Exploits natural “bursty” patterns in speech to skip redundant operations.
- Architecture shaping – Using compact temporal convolutional (TCN) and recurrent neural networks (RNNs) for low-latency streaming audio.
Combined, these techniques allow 33× fewer effective operations—making it possible to run speech enhancement, wake word detection, SLU, and ANC simultaneously on low-power earbuds.
A Concrete Example: Smart MEMS MIC + AI Stack
A typical speech enhancement model has ~6M parameters (~24 MB in float precision). Through compression:
- With INT8 quantization → ~6 MB
- With 90% sparsity → ~600 KB
- With activation reuse → ~700 KB total footprint
This reduction enables coexistence with other models (wake word, voice ID, ANC) in 1 MB SRAM without external DRAM.
When paired with Smart MEMS Microphones, the result is a system that:
- Runs low-latency denoising at 4–8 ms
- Consumes just 1–2 mW for always-on operation
- Extends battery life even with multi-feature AI workloads
👉 Learn more about our product here: Smart MEMS Microphone
Why Smart MEMS Microphones Matter
While compression makes AI feasible, audio quality starts at the microphone. MEMS MIC technology ensures:
- High SNR and low noise floor, critical for accurate speech recognition.
- Wide dynamic range for both soft and loud environments.
- Low power operation to match the efficiency of compressed AI stacks.
Smart MEMS MICs are not just sensors—they are AI enablers. By capturing cleaner signals, they reduce downstream model complexity and help achieve reliable performance under tight power and memory budgets.
Looking Ahead
As hearables converge with AI-powered features, the collaboration between efficient AI models and advanced Smart MEMS Microphones will define the next generation of consumer audio.
At SISTC, we’re committed to driving this transformation—helping OEMs pack more brains into buds without blowing up the battery budget.
📖 Related Reading: